在第九天資料倉儲中常見的資料模型設計中有提到,snapshot 是對資料源異動常見的處理方式,而 dbt 中也提供了這個功能,那就是 dbt snapshot。
建立 dbt snapshot 時,只需要在 snapshots 的資料夾下加入一個 .sql 檔,並加入一些 config 就能完成。
一般來說,snapshot 會對整張表進行,因此 sql 語法的部分通常只需要用 select * from ... 就可以了,比較複雜的地方是 config,
target_schema: 資料源的 snapshot 會存在資料庫中的哪個 schema。
strategy: 有 timestamp 跟 check。一般來說只要資料源有這筆資料最近一次更新的時間就可以用 timestamp 。如果沒有的話建議你換公司。如果沒有的話,就要用 check。
unique_key: 資料源的 pimary_key,通常是以 id 結尾,而這個 id 在這張表中是獨一無二的。以 crm.companies 來說,每一列都是一間 companay 因此用 company_id。
updated_at:這個 是跟 strategy = timestamp 共用的 config,告訴他是用哪一個欄位做最後有更新的認定。像是在我的 crm.companies 裡面有 updated_at 以及 _etl_udpated_at 這兩個跟上次更新相關的時間,這邊用 updated_at 是因為他是指資料源更新的時間。(_etl_updated_at 通常是指這一列在資料倉儲中最近一次更新的時間(通常就是跟資料源 sync 的時間。)
在寫完 .sql 的程式碼後,在下面的 Terminal 輸入 dbt snapshot 就會開始對資料源做 snapshot 了。做完後,在資料庫中呈現的欄位會如下所示,相比原本的 crm.companies 多出了四個欄位,重要的是最後兩個欄位 dbt_valid_from 以及 dbt_valid_to
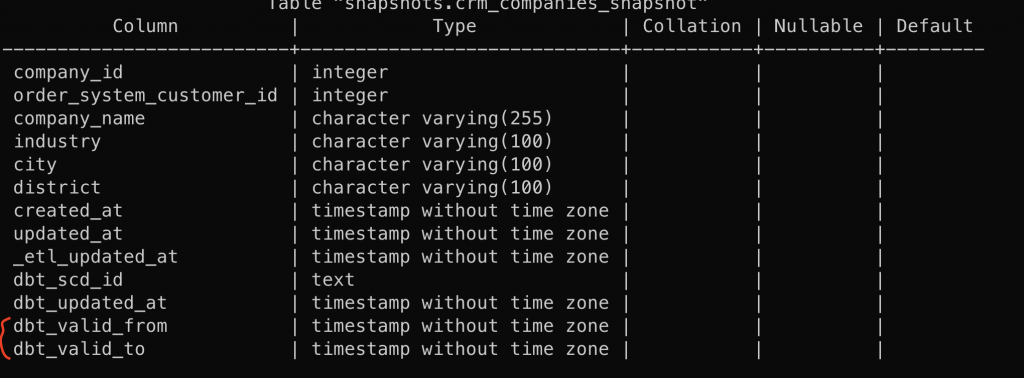
下圖則是 crm.companies 以及 snapshots.crm_companies_snapshot 的對照:

可以看到 dbt_valid_from 基本上就是 updated_at,意思是 company_id = 1 的公司在 2024-03-08 17:01:11 之後,他的名字是 McBurger,位在台北市。
但某一天, McBurger 搬到台北了,資料源的資料也有所更新,變成下面:
可以看到 updated_at 變成更新的時間,這時候如果再跑一次 dbt snapshot ,snapshots.crm_companies_snapshot 就會變成下圖:

可以看到 company_id = 1 的公司 直到 2024-10-04 都在台北市,但之後就搬到台中市了。我們也可以知道採取 timestamp 這個 strategy,就是透過 updated_at 的欄位去找出上次資料更新後,有哪幾筆資料有新的異動,接著比對 company_id之後作出 dbt_valid_from 以及 dbt_valid_to
以批量處理來說,在每次的資料源更新後,就可以跑 snapshot,去擷取當次有異動的幾筆紀錄,如此一來便能最大化保存歷史的異動紀錄。但因為是批量處理,還是沒辦法保留完整的異動紀錄:舉例來說,資料源在資料倉儲的更新可能是一天同步一次,但一天內同一筆資料可能異動了三四次,批量的同步就只能同步到最新的狀態,中間的變動就會視同消失了。如果想保留所有的歷史異動,可能就要資料同步時,就採取 CDC 的做法,但這就是非常工程師的領域了,有興趣可以去參考團友的文章。


 iThome鐵人賽
iThome鐵人賽